Welcome to the Mannheim Open Science Day Reprohack
![]()
Thank you ! 🙏
University Of Mannheim Open Science Office!
https://www.uni-mannheim.de/open-science/open-science-office/
![]()
![]()
Especially:
Philipp Zumstein ✨
David Morgan ✨
ReproHack hackpad ➡️ hackmd.io notepad
Who is my favorite animated character?
Stitch!

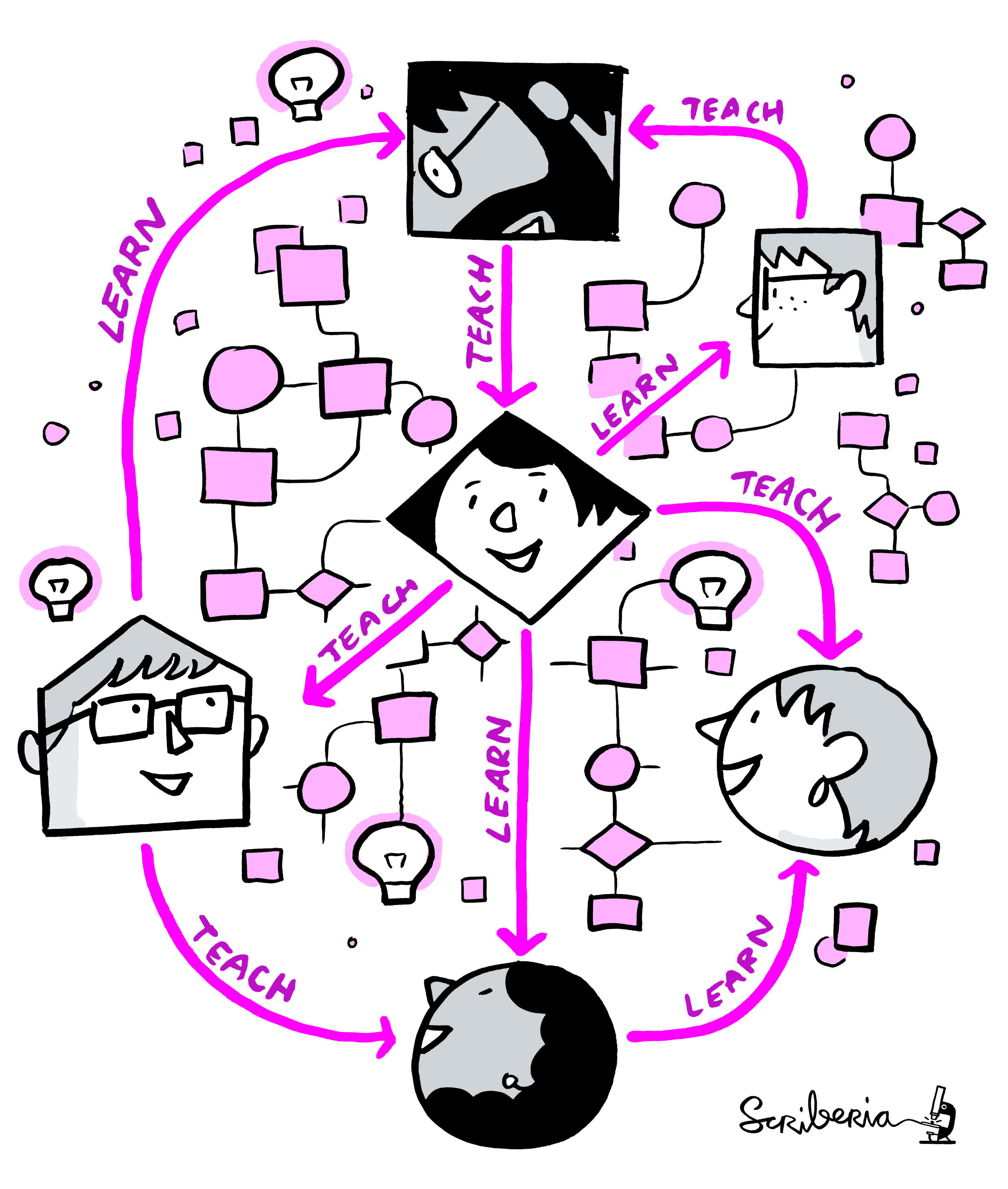
Additional Considerations
Reproducibility is hard!
Submitting authors are incredibly brave!
Thank you Authors! 🙌
Without them there would be no ReproHack.
Show gratitude and appreciation for their efforts. 🙏
Constructive criticism only please!
🔍 Reproducing & Reviewing

Selecting Papers
Information submitted by authors:
Languages / tools used (tags)
Why you should attempt the paper.
No. attempts No. times reproduction has been attempted
Mean Repro Score Mean reproducibility score (out of 10)
- lower == harder!
Register paper using template in hackpad:
### **Paper:** <Title of the paper reproduced> **Reviewers:** Reviewer 1, Reviewer 2 etc.
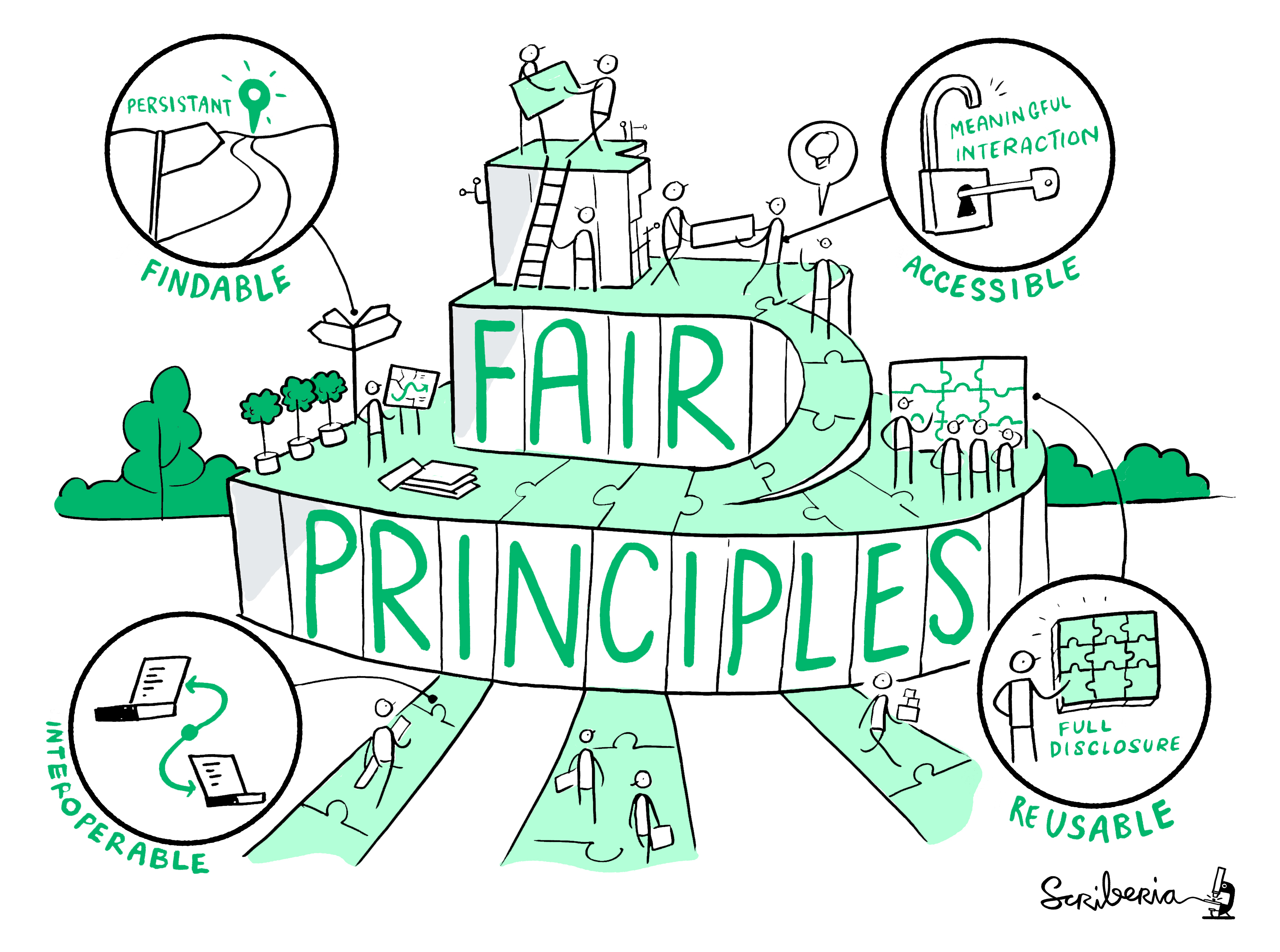
🔍 For FAIR materials
Useful User Perspectives
New User

Invested User

Feedback as a community member
Acknowledge author effort
Give feedback in good faith
Focus on community benefits and system level solutions
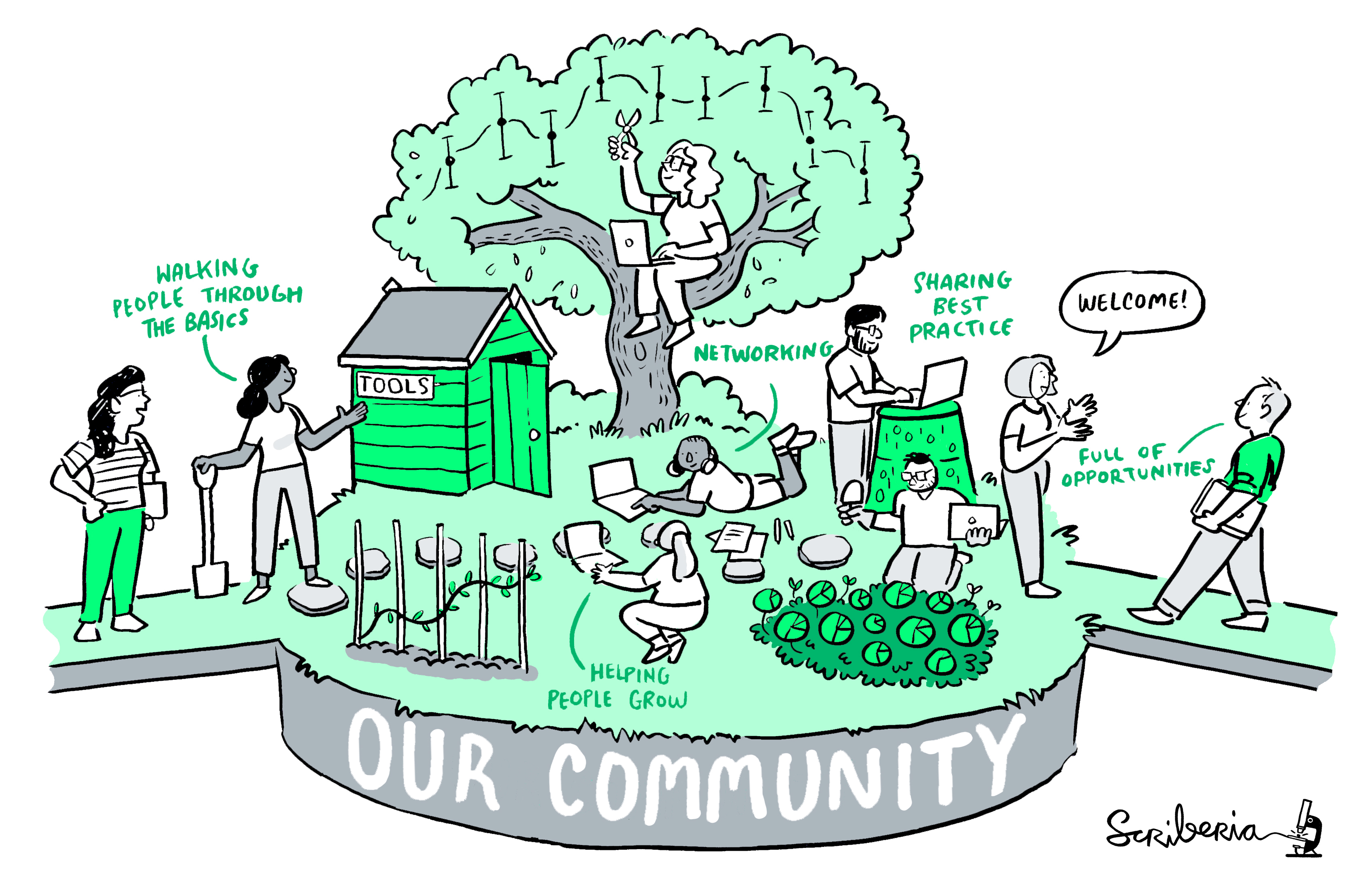
Help build convention on what a Research Compendium should be and how we should be able to use it

tl;dr: Don’t be this guy!

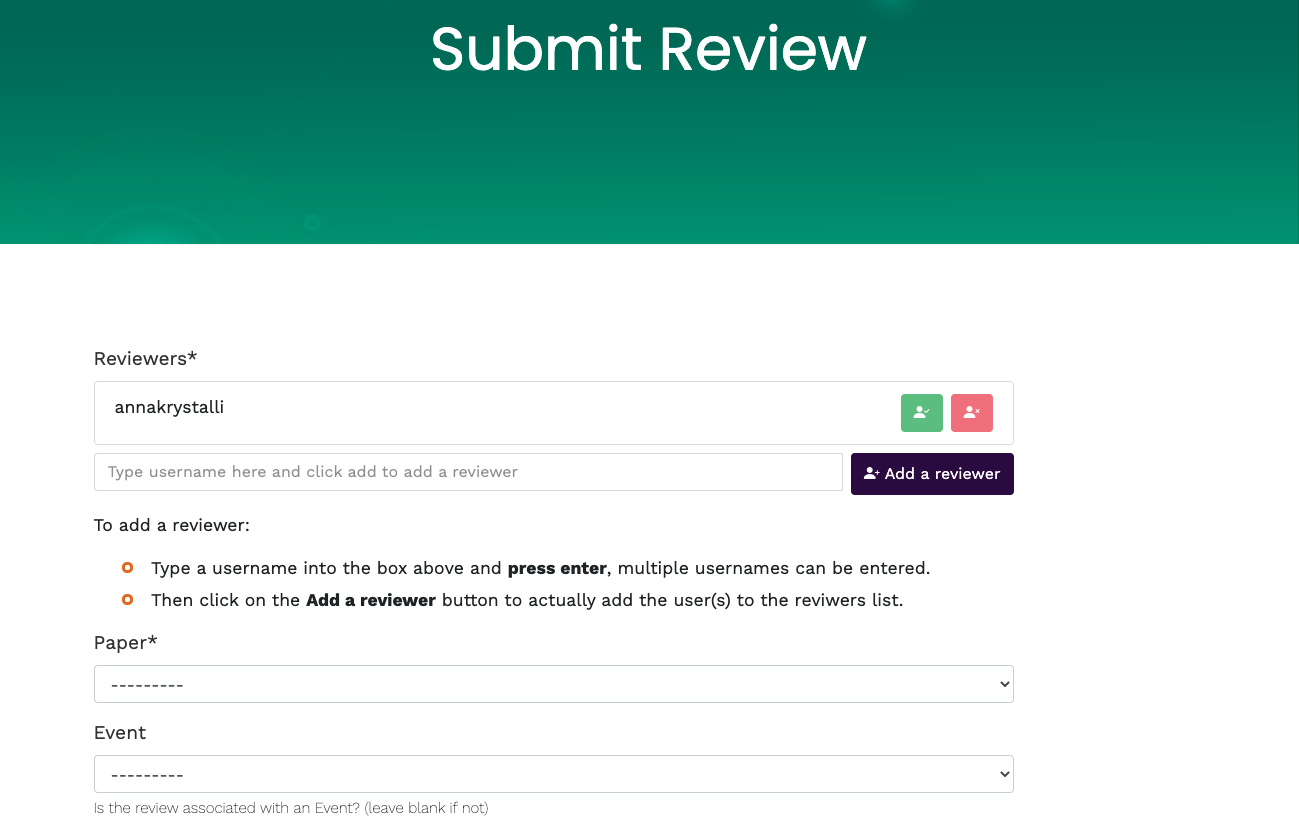
Submit review
Sign up / Log in
New Review: reprohack.org/review/new
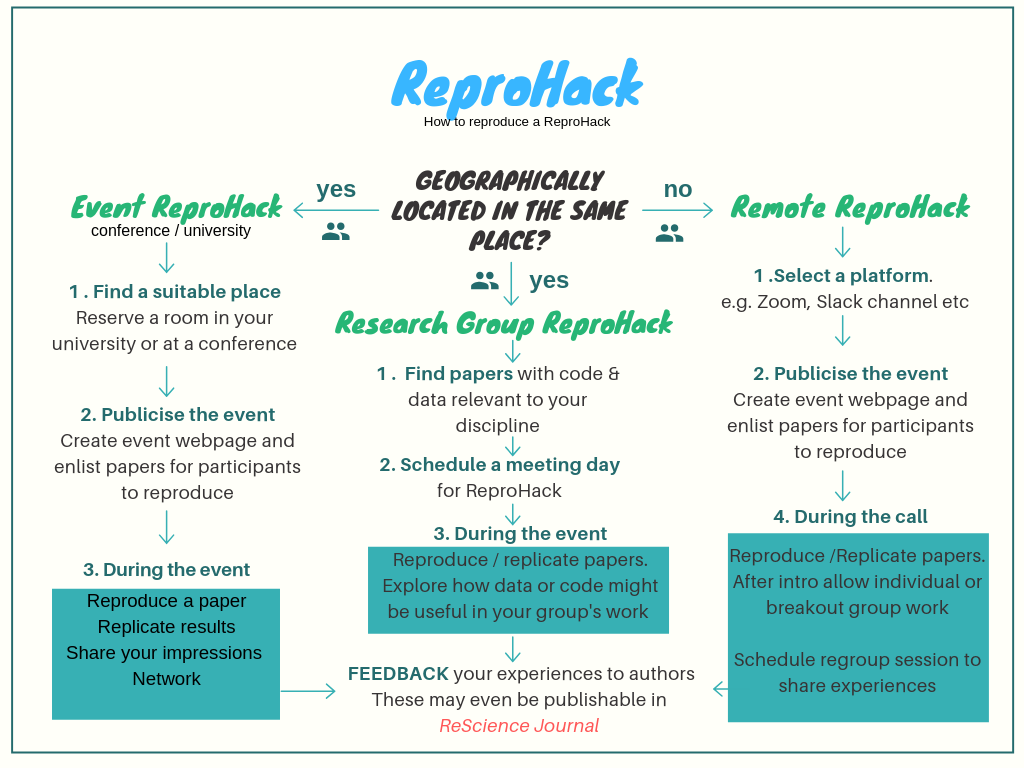
Did you enjoy ReproHacking? Get involved!
reprohack.org
Chat to us: ![Slack]()
Host your own event!
Look out for train-the-trainer events!
Submit your own papers!
Many ways to ReproHack!
Acknowledgements
Images throughout the slides watermarked with Scriberia were created by Scriberia for The Turing Way community and is used under a CC-BY licence:
- The Turing Way Community, & Scriberia. (2019, July 11). Illustrations from the Turing Way book dashes. Zenodo. http://doi.org/10.5281/zenodo.3332808